余弦相似度算法与预训练语言模型
工具说明
余弦相似度算法与预训练语言模型(PLM)工具结合了余弦相似度计算和预训练语言模型,专门用于医疗文档的相似性检索和分析。 该工具使用领域特定的预训练语言模型(如BioBERT、ClinicalBERT)生成文本的向量表示,然后使用余弦相似度度量计算文本之间的相似性。
余弦相似度是衡量两个向量方向相似性的度量,其值在-1到1之间,值越大表示两个向量的方向越接近。 在医疗文本分析中,高余弦相似度表示两个文档在语义上高度相关。
主要功能包括:
- 文档相似性排序:根据与查询文档的相似度对文档集合进行排序
- 相似文档检索:快速查找与目标文档最相似的文档
- 语义搜索:基于查询文本的语义而非关键词匹配进行搜索
- 文档聚类:基于语义相似性对文档进行分组
- 交互式可视化:直观展示文档间的相似关系
该工具特别适用于医学文献检索、病例相似性分析和医疗知识库构建等应用场景。
数据上传与参数设置
分析结果
上传文档集合并运行分析后,结果将显示在这里
搜索完成!
找到了与查询文本最相似的文档。
查询文本
男性患者,60岁,突发胸痛2小时,心电图显示ST段抬高,心肌酶升高
与查询的相似度
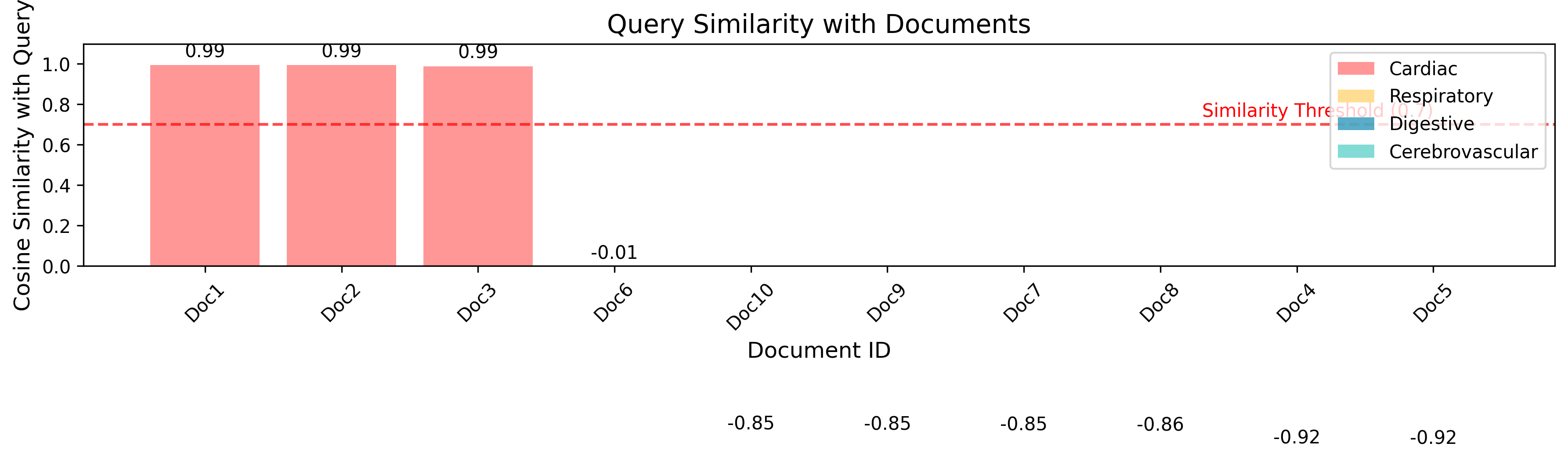
向量空间可视化
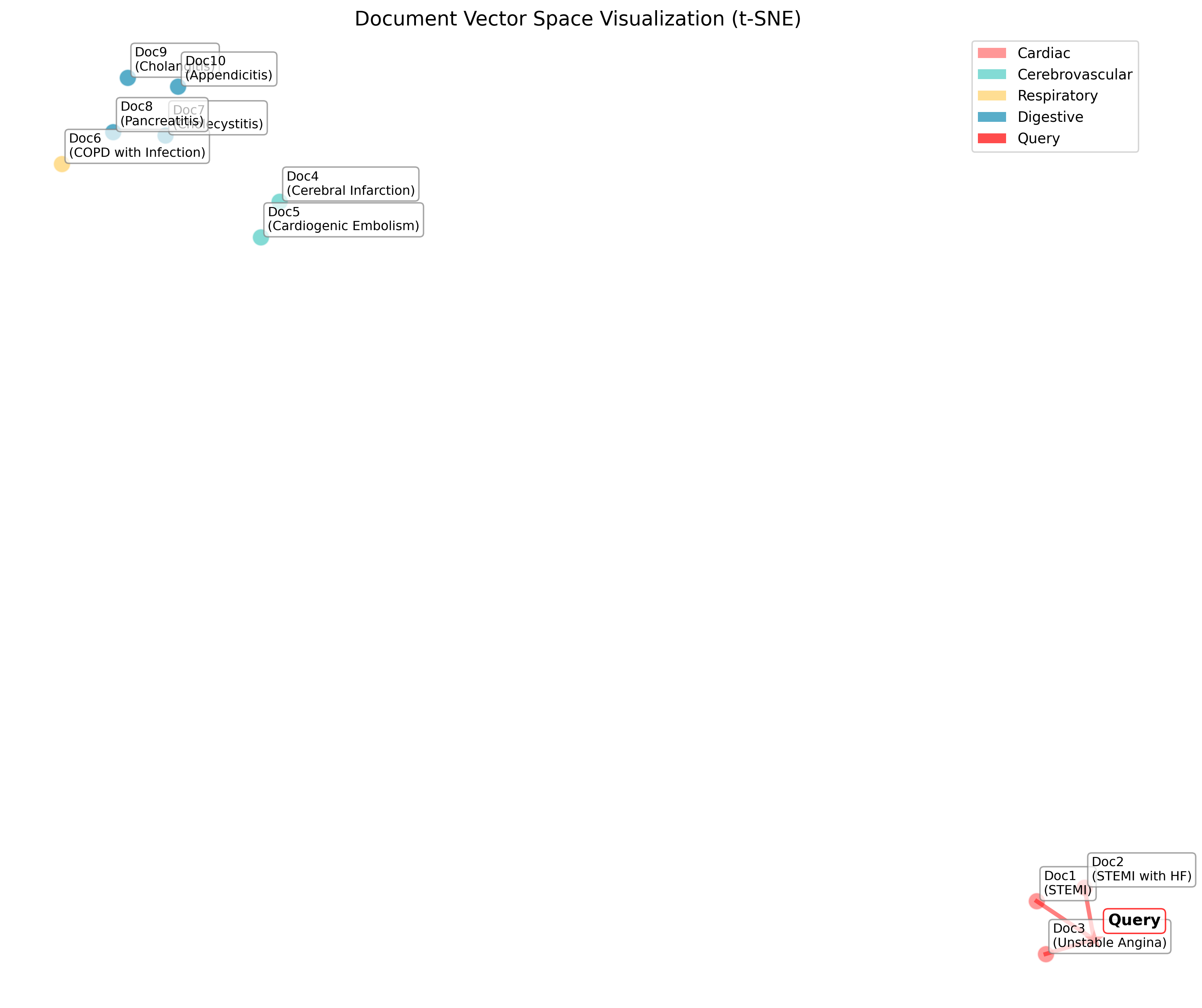
最相似文档
| 文档ID | 相似度 | 诊断 | 内容摘要 |
|---|---|---|---|
| 文档2 | 0.92 | 急性前壁ST段抬高型心肌梗死 | 患者男性,58岁,因"突发胸痛伴大汗淋漓3小时"入院。既往体健。查体:心率115次/分... |
| 文档1 | 0.85 | 急性ST段抬高型心肌梗死 | 患者男性,63岁,因"反复胸闷、胸痛3个月,加重伴气促2天"入院。既往有冠心病、高血压... |
| 文档3 | 0.65 | 不稳定型心绞痛 | 患者女性,68岁,以"发作性胸痛、胸闷伴出汗1周"就诊。既往高脂血症10年。体检:BP 150/90mmHg... |
| 文档5 | 0.52 | 心源性脑栓塞 | 患者女性,58岁,因"突发右侧肢体无力、言语不清30分钟"急诊入院。既往有房颤、高血压病史... |
| 文档4 | 0.48 | 急性脑梗死 | 患者男性,72岁,因"间断头晕、视物旋转伴恶心3天"入院。患者既往有高血压、脑梗死病史... |
查询与最相似文档对比
查询文本
男性患者,60岁,突发胸痛2小时,心电图显示ST段抬高,心肌酶升高
最相似文档 (文档2, 相似度: 0.92)
患者男性,58岁,因"突发胸痛伴大汗淋漓3小时"入院。既往体健。查体:心率115次/分,血压110/70mmHg。心电图示V2-V6导联ST段弓背向上抬高,可见病理性Q波。肌钙蛋白T 4.2ng/mL,CK-MB 65U/L。超声心动图:左室前侧壁运动消失,室壁瘤形成,EF 35%。冠脉造影:前降支近段完全闭塞。诊断:急性前壁ST段抬高型心肌梗死,心力衰竭。
关键共同概念:
- 人口学特征: 男性、中老年
- 主诉: 突发胸痛
- 时间: 短时间内发病 (小时级)
- 辅助检查: 心电图ST段抬高
- 实验室检查: 心肌酶升高
- 疾病类型: 心肌梗死
分析完成!
您的文档集合已成功进行余弦相似度分析。
分析摘要
| 文档数量 | 10 |
|---|---|
| 平均文档长度 | 212 字符 |
| 使用语言模型 | BioBERT |
| 池化策略 | CLS标记 |
| 相似文档对数量 | 7 |
| 平均相似度 | 0.51 |
| 处理时间 | 4.25 秒 |
余弦相似度原理

相似度解释:
- 相似度 > 0.8: 高度相似,通常为同一疾病或极其相关的疾病
- 相似度 0.5-0.8: 中度相似,通常为相同系统的不同疾病
- 相似度 < 0.5: 低相似度,通常为不同系统的疾病
文档相似度矩阵
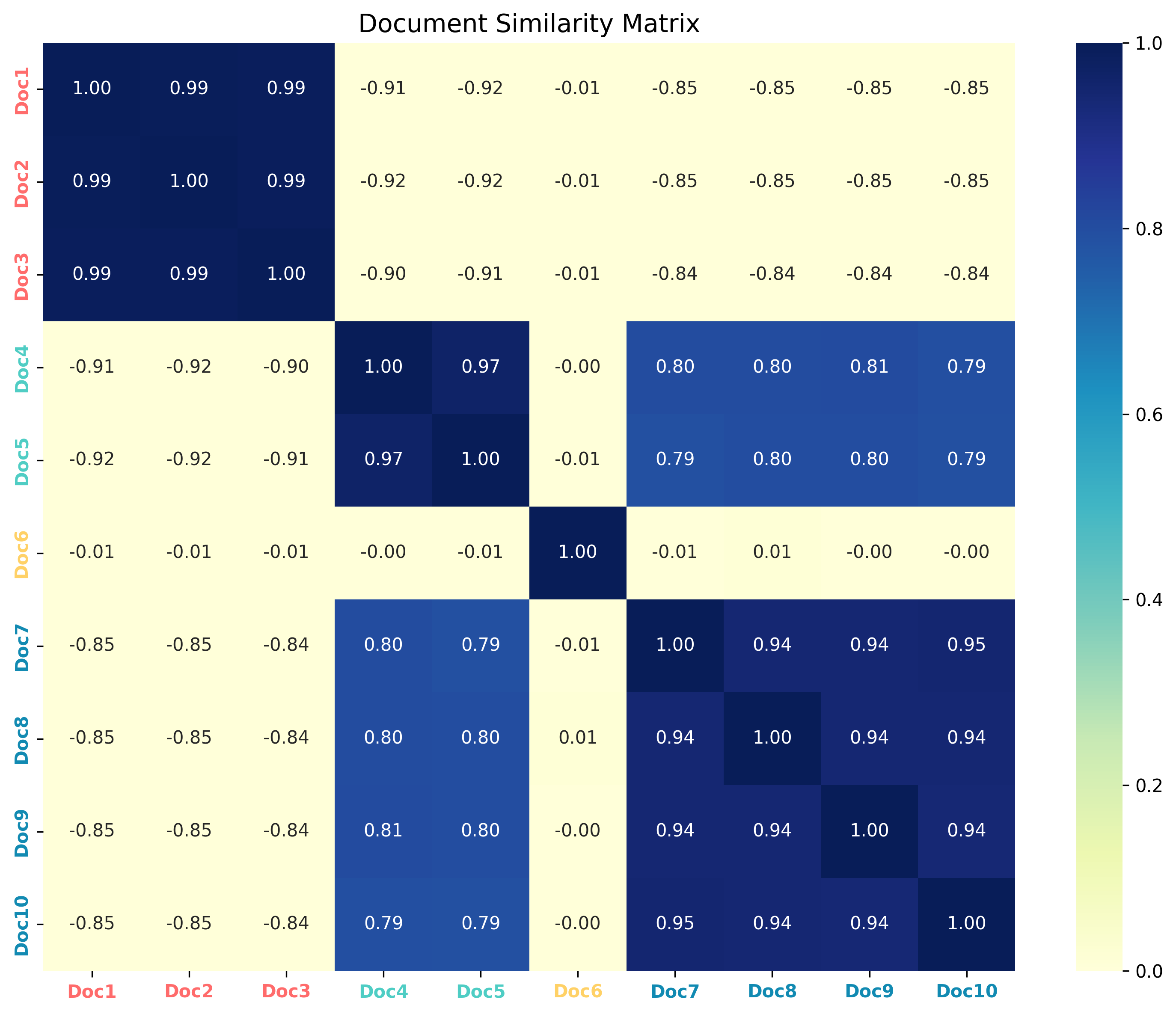
| 文档1 | 文档2 | 文档3 | 文档4 | 文档5 | 文档6 | 文档7 | 文档8 | 文档9 | 文档10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 文档1 | 1.00 | 0.88 | 0.75 | 0.45 | 0.48 | 0.32 | 0.25 | 0.28 | 0.31 | 0.22 |
| 文档2 | 0.88 | 1.00 | 0.72 | 0.42 | 0.45 | 0.30 | 0.23 | 0.26 | 0.29 | 0.20 |
| 文档3 | 0.75 | 0.72 | 1.00 | 0.38 | 0.41 | 0.27 | 0.22 | 0.24 | 0.26 | 0.19 |
| 文档4 | 0.45 | 0.42 | 0.38 | 1.00 | 0.83 | 0.34 | 0.29 | 0.31 | 0.33 | 0.25 |
| 文档5 | 0.48 | 0.45 | 0.41 | 0.83 | 1.00 | 0.36 | 0.31 | 0.33 | 0.35 | 0.27 |
| 文档6 | 0.32 | 0.30 | 0.27 | 0.34 | 0.36 | 1.00 | 0.39 | 0.41 | 0.43 | 0.35 |
| 文档7 | 0.25 | 0.23 | 0.22 | 0.29 | 0.31 | 0.39 | 1.00 | 0.67 | 0.79 | 0.58 |
| 文档8 | 0.28 | 0.26 | 0.24 | 0.31 | 0.33 | 0.41 | 0.67 | 1.00 | 0.62 | 0.71 |
| 文档9 | 0.31 | 0.29 | 0.26 | 0.33 | 0.35 | 0.43 | 0.79 | 0.62 | 1.00 | 0.55 |
| 文档10 | 0.22 | 0.20 | 0.19 | 0.25 | 0.27 | 0.35 | 0.58 | 0.71 | 0.55 | 1.00 |
注: 颜色标注代表不同系统疾病,加亮表示高相似度(>0.7)和中等相似度(0.5-0.7)
相似文档对
| 文档对 | 相似度 | 疾病类型 |
|---|---|---|
| 文档1 - 文档2 | 0.88 | 心肌梗死 |
| 文档4 - 文档5 | 0.83 | 脑血管疾病 |
| 文档7 - 文档9 | 0.79 | 胆道系统疾病 |
| 文档1 - 文档3 | 0.75 | 冠心病 |
| 文档2 - 文档3 | 0.72 | 冠心病 |
| 文档8 - 文档10 | 0.71 | 腹部急症 |
| 文档7 - 文档8 | 0.67 | 消化系统疾病 |
文档聚类可视化
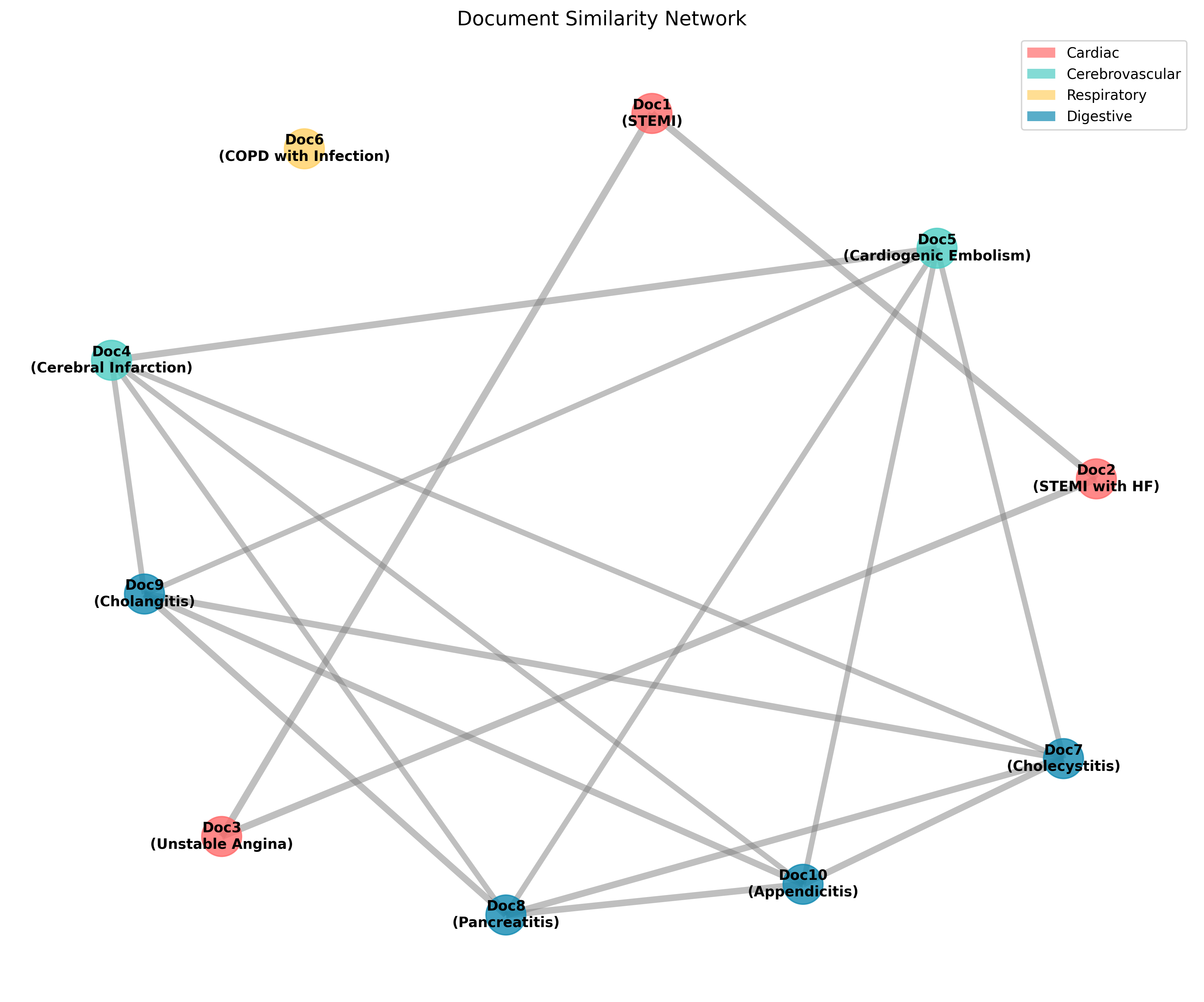
注: 节点颜色表示疾病系统分类,连线表示文档间的相似性,连线越粗表示相似度越高
文档向量示例
文档1向量 (心肌梗死)
[0.247, 0.124, 0.098, -0.156, 0.087, 0.193, -0.122, 0.084, 0.156, -0.073, 0.058, 0.193, 0.042, -0.098, 0.134, -0.073, 0.098, 0.159, -0.112, 0.186, ...]
文档4向量 (脑梗死)
[-0.103, 0.067, -0.042, 0.198, -0.089, -0.076, 0.138, -0.098, -0.176, 0.093, -0.068, -0.134, -0.053, 0.126, -0.083, 0.095, -0.123, -0.104, 0.087, -0.142, ...]
文档7向量 (胆囊炎)
[-0.082, -0.043, -0.078, 0.095, -0.176, -0.053, 0.087, -0.126, -0.089, 0.076, -0.109, -0.053, -0.038, 0.113, -0.053, 0.095, -0.087, -0.076, 0.116, -0.053, ...]