深度学习编码
工具说明
深度学习编码工具使用先进的神经网络模型对临床和诊断数据进行编码,将复杂的多维数据转换为低维度的表示向量。 该工具支持多种深度学习架构,包括多层感知机(MLP)、卷积神经网络(CNN)和自编码器(Autoencoder), 能够处理各种类型的医疗数据,如检验结果、影像特征和时序临床指标等。
主要功能包括:
- 自动特征工程:通过深度神经网络自动学习数据中的关键特征
- 降维编码:将高维医疗数据压缩为低维表示,便于后续分析
- 非线性特征提取:捕捉数据中复杂的非线性关系
- 异常检测:识别异常数据点,可用于疾病风险评估
- 多模态整合:统一编码不同来源和类型的医疗数据
该工具支持CSV、Excel和JSON格式的结构化数据文件,并提供直观的模型训练和评估界面。
数据上传与参数设置
编码结果
上传数据并运行编码后,结果将显示在这里
编码完成!
您的临床数据已成功通过深度学习模型进行编码。
数据与模型摘要
| 数据样本数 | 12 |
|---|---|
| 特征数量 | 38 |
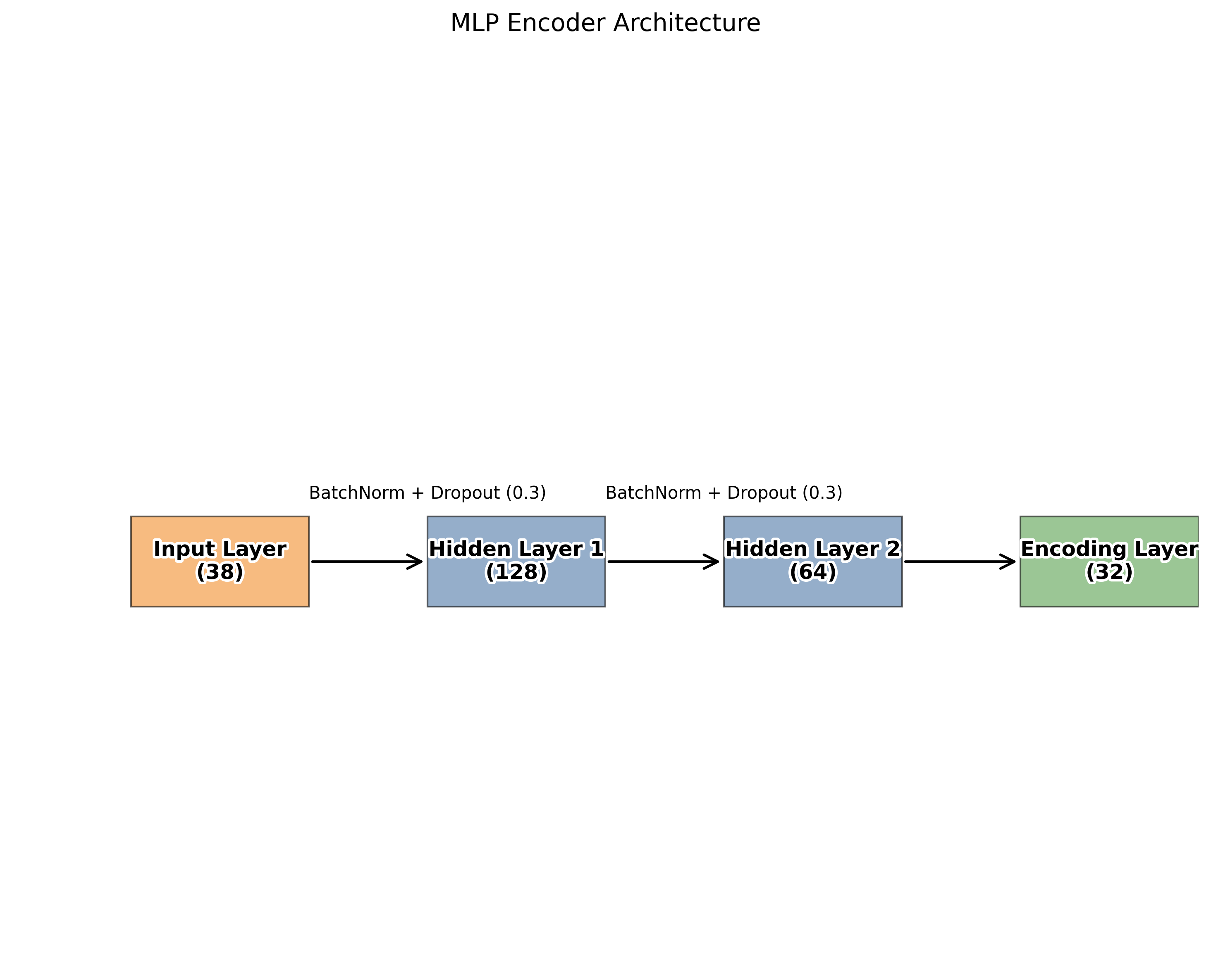
| 模型类型 | 多层感知机 (MLP) |
| 隐藏层 | [128, 64, 32] |
| 编码维度 | 32 |
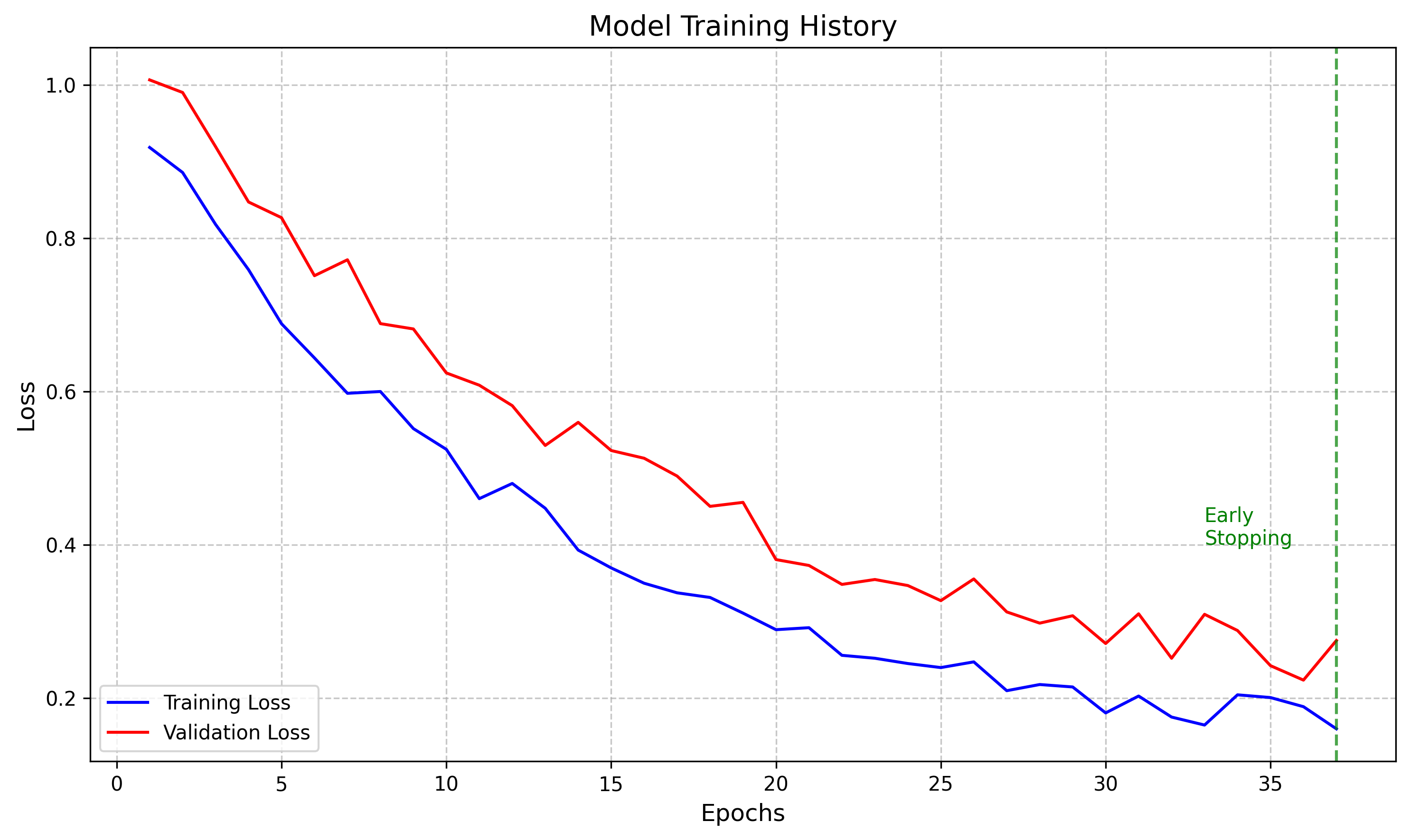
| 训练轮数 | 37 (早停) |
| 处理时间 | 18.5 秒 |
模型架构
训练过程
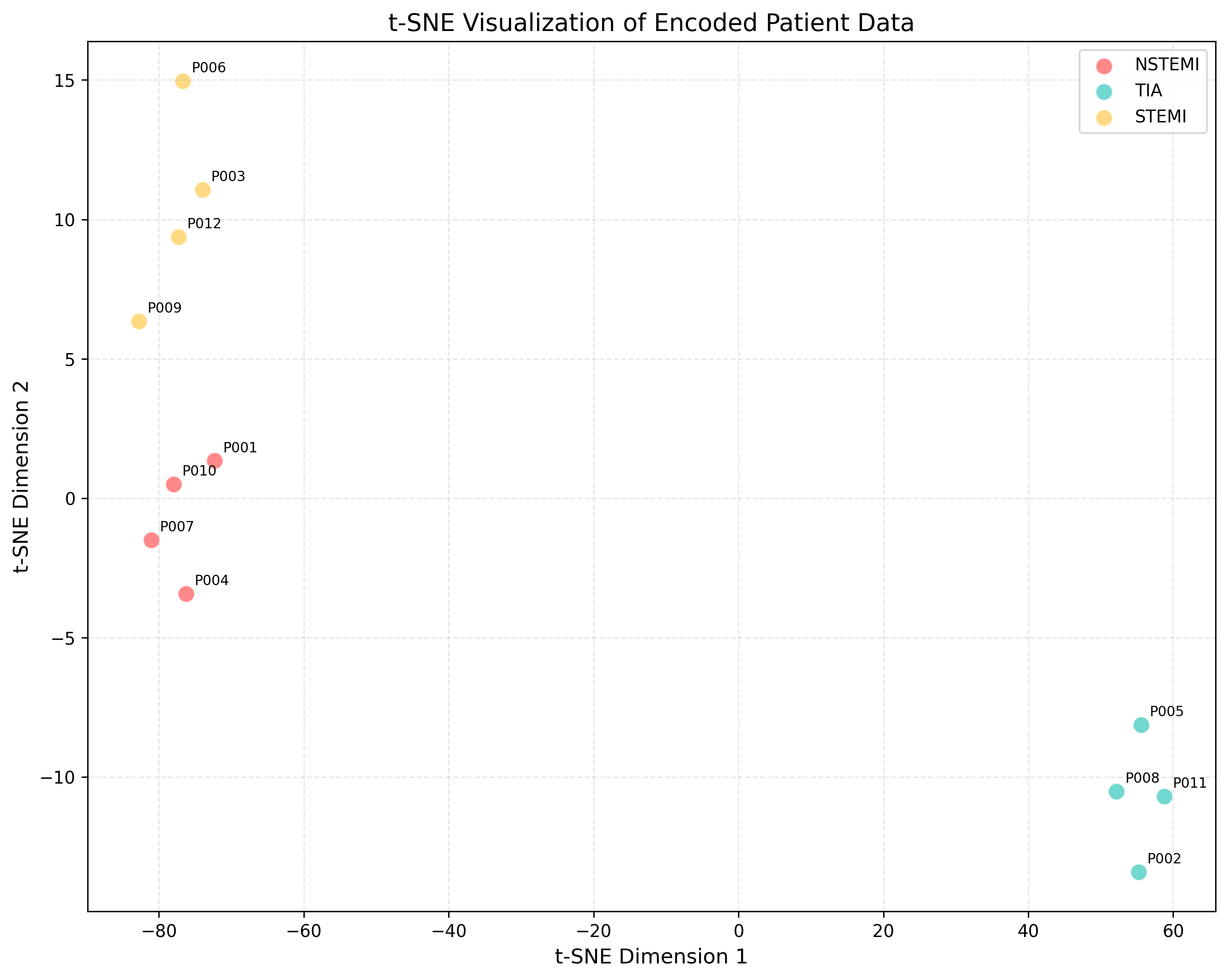
编码结果可视化
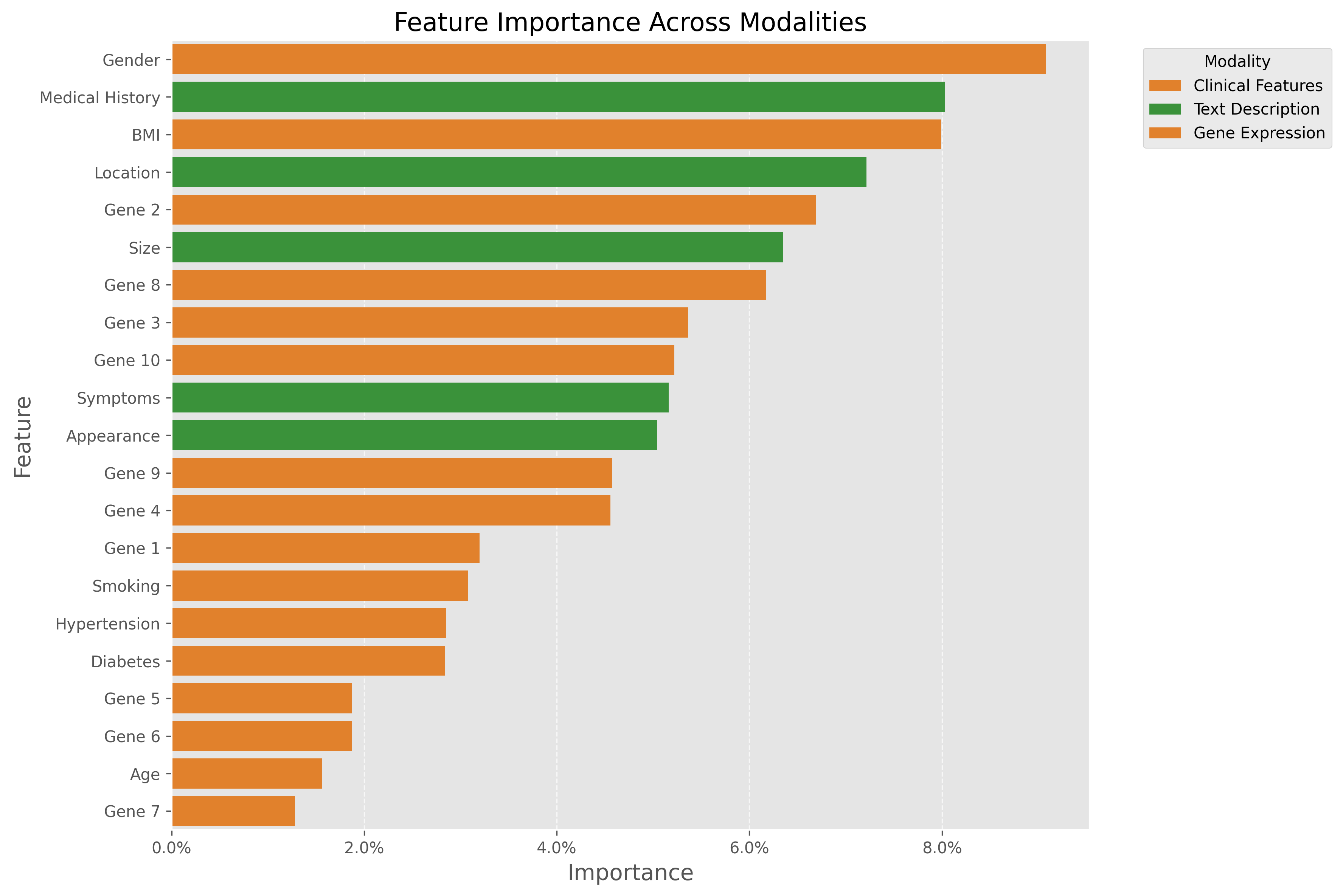
特征重要性
| 特征 | 重要性 | 可视化 |
|---|---|---|
| troponin_t | 0.187 |
|
| nt_pro_bnp | 0.165 |
|
| crp | 0.143 |
|
| ck_mb | 0.129 |
|
| chest_pain | 0.112 |
|
| age | 0.098 |
|
| ddimer | 0.085 |
|
| systolic_bp | 0.078 |
|
| heart_rate | 0.072 |
|
| glucose | 0.068 |
|
样本编码向量
| 样本ID | 诊断 | 编码向量(前5维) |
|---|---|---|
| P001 | NSTEMI | [0.374, 0.155, 0.126, 0.215, 0.039, ...] |
| P002 | TIA | [-0.055, 0.274, -0.160, 0.231, 0.133, ...] |
| P003 | STEMI | [0.340, 0.119, 0.290, 0.107, 0.016, ...] |
| P004 | NSTEMI | [0.366, 0.147, 0.118, 0.208, 0.032, ...] |
| P005 | TIA | [-0.063, 0.267, -0.168, 0.225, 0.127, ...] |
| P006 | STEMI | [0.348, 0.125, 0.298, 0.112, 0.022, ...] |
| P007 | NSTEMI | [0.370, 0.151, 0.122, 0.212, 0.035, ...] |
| P008 | TIA | [-0.058, 0.271, -0.164, 0.228, 0.130, ...] |
| P009 | STEMI | [0.344, 0.122, 0.294, 0.110, 0.019, ...] |
| P010 | NSTEMI | [0.372, 0.153, 0.124, 0.214, 0.037, ...] |
| P011 | TIA | [-0.060, 0.270, -0.166, 0.227, 0.129, ...] |
| P012 | STEMI | [0.346, 0.124, 0.296, 0.111, 0.021, ...] |
完整编码向量示例 (P001, 32维)
[0.374, 0.155, 0.126, 0.215, 0.039, 0.066, -0.142, 0.097, 0.046, 0.223, 0.128, -0.049, 0.180, 0.088, -0.081, 0.112, 0.043, -0.061, 0.196, 0.137, 0.082, 0.211, 0.028, 0.172, -0.119, 0.056, 0.121, 0.063, -0.038, 0.153, 0.069, 0.107]