自然语言处理编码
工具说明
自然语言处理(NLP)编码工具用于处理临床文本数据,提取医疗实体并生成语义表示。 该工具利用先进的NLP技术,如命名实体识别、依存句法分析和语义向量化,将非结构化临床文本转换为结构化数据和语义向量。
主要功能包括:
- 医疗实体识别:自动识别文本中的疾病、症状、药物、检查、数值等医疗实体
- 实体关系提取:识别实体之间的关系,如"治疗"、"诊断"、"表现"等
- 语义向量化:将文本转换为高维语义向量,支持相似文本检索和语义分析
- 医疗术语标准化:将不同表达的医疗概念映射到标准术语库
该工具支持TXT、CSV和JSON格式的文本文件,适用于处理病历、医学报告和临床记录等医疗文本数据。
数据上传与参数设置
编码结果
上传文本数据并运行编码后,结果将显示在这里
编码完成!
您的临床文本已成功进行NLP处理和编码。
处理结果摘要
| 处理文本数 | 1 |
|---|---|
| 文本长度 | 567 字符 |
| 识别实体数 | 56 |
| 提取关系数 | 22 |
| 嵌入向量维度 | 768 |
| 处理时间 | 3.45 秒 |
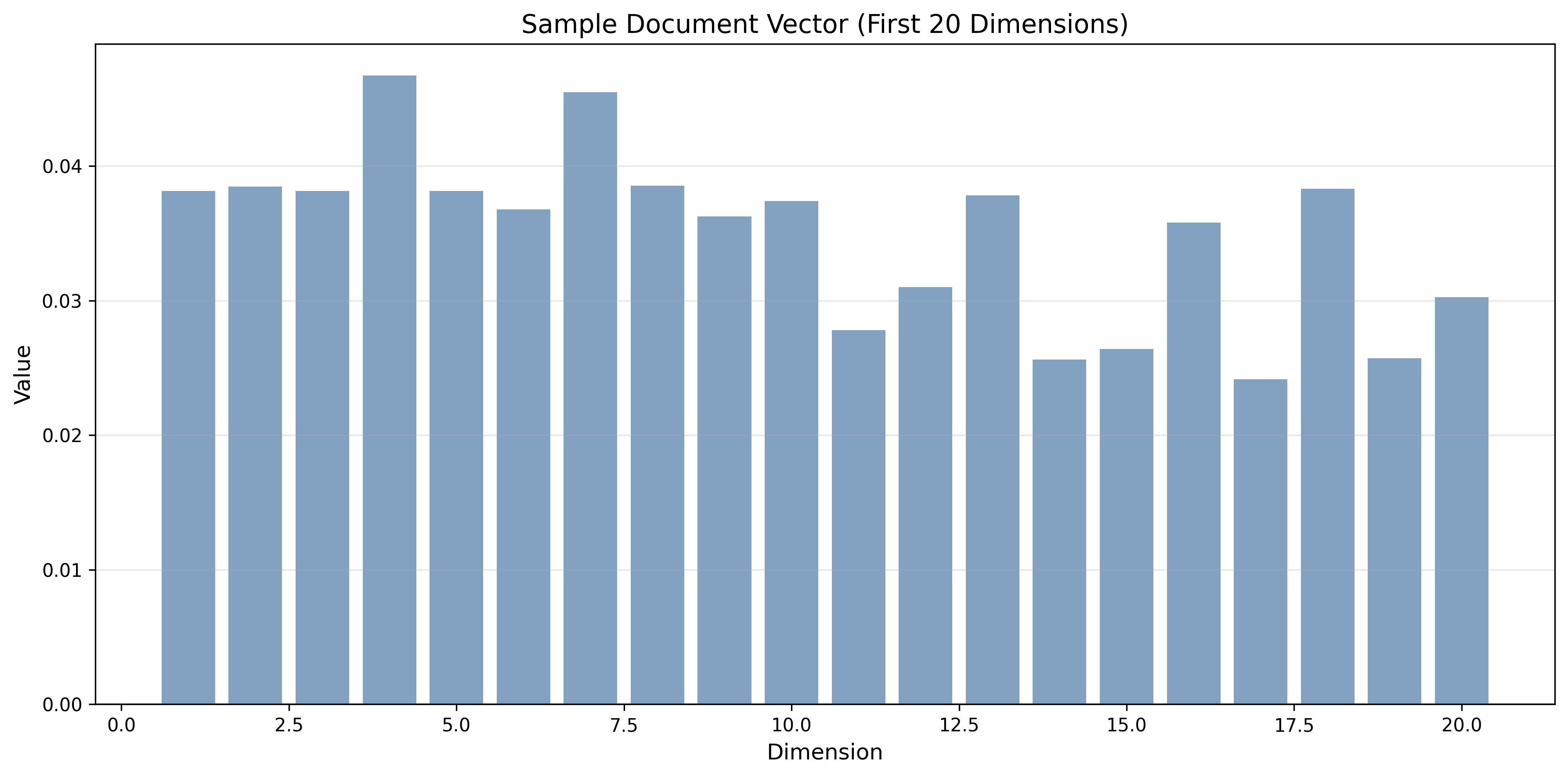
实体统计
命名实体识别结果
患者,男,67岁,因"反复胸闷、气促伴心前区疼痛3个月,加重2天"入院。患者3个月前无明显诱因出现胸闷、气促,伴心前区闷痛,呈持续性,活动后加重,休息后可缓解。2天前症状明显加重,持续性胸闷、心前区疼痛,伴出汗、恶心。既往高血压病史10年,血压最高达180/100mmHg,长期口服苯磺酸氨氯地平5mg,每日1次;2型糖尿病史7年,空腹血糖8-10mmol/L,口服二甲双胍和阿卡波糖治疗,血糖控制尚可。查体:BP 165/95mmHg,HR 94次/分,R 21次/分,神志清,两肺呼吸音粗,未闻及干湿啰音,心率94次/分,律齐,心音低钝,各瓣膜听诊区未闻及病理性杂音,腹软,无压痛。化验检查:心肌肌钙蛋白I 2.8ng/mL,肌酸激酶同工酶 42U/L,B型钠尿肽 920pg/mL。心电图:窦性心动过速,V1-V4导联ST段抬高0.2-0.4mV。超声心动图:左室前壁运动减弱,射血分数45%。冠状动脉造影:前降支近段90%狭窄,回旋支中段70%狭窄,右冠状动脉近段80%狭窄。诊断:1.急性ST段抬高型心肌梗死;2.冠状动脉粥样硬化性心脏病,三支病变;3.高血压病2级,很高危;4.2型糖尿病。
提取的实体列表 (部分)
| 实体 | 类型 | 标准化术语 |
|---|---|---|
| 患者 | 人物 | - |
| 男 | 人物 | - |
| 67岁 | 年龄 | - |
| 胸闷 | 症状 | 胸部不适 |
| 气促 | 症状 | 呼吸急促 |
| 心前区 | 身体部位 | 前胸部 |
| 疼痛 | 症状 | 疼痛 |
| 3个月 | 时间 | - |
| 加重 | 症状 | 症状恶化 |
| 2天 | 时间 | - |
| 高血压 | 疾病 | 高血压 |
| 苯磺酸氨氯地平 | 药物 | 氨氯地平 |
| 2型糖尿病 | 疾病 | II型糖尿病 |
| 二甲双胍 | 药物 | 二甲双胍 |
| 阿卡波糖 | 药物 | 阿卡波糖 |
| 治疗 | 治疗 | - |
| 化验检查 | 检查 | 实验室检查 |
| 心电图 | 检查 | 心电图 |
| 超声心动图 | 检查 | 心脏超声 |
| 冠状动脉造影 | 检查 | 冠脉造影 |
实体关系图谱
向量表示可视化