独热编码 (One-Hot Encoding)
工具说明
独热编码(One-Hot Encoding)是一种将序列数据转换为机器学习模型可用格式的方法。它将每个核苷酸(A、T、G、C)表示为一个四维向量, 其中只有一个维度为1,其余维度为0。例如:
- A 表示为 [1, 0, 0, 0]
- T 表示为 [0, 1, 0, 0]
- G 表示为 [0, 0, 1, 0]
- C 表示为 [0, 0, 0, 1]
这种编码方式保留了序列的位置信息,是深度学习模型处理DNA/RNA序列数据的常用输入格式。 该工具支持FASTA格式的序列文件,可以快速将多条序列同时转换为独热编码矩阵。
数据上传与参数设置
编码结果
上传序列数据并运行编码后,结果将显示在这里
编码完成!
您的序列数据已成功转换为独热编码格式。
编码结果摘要
| 处理序列数 | 5 |
|---|---|
| 序列平均长度 | 124 bp |
| 编码维度 | 4 (A,T,G,C) |
| 编码矩阵形状 | [5, 124, 4] |
| 处理时间 | 0.12 秒 |
序列组成
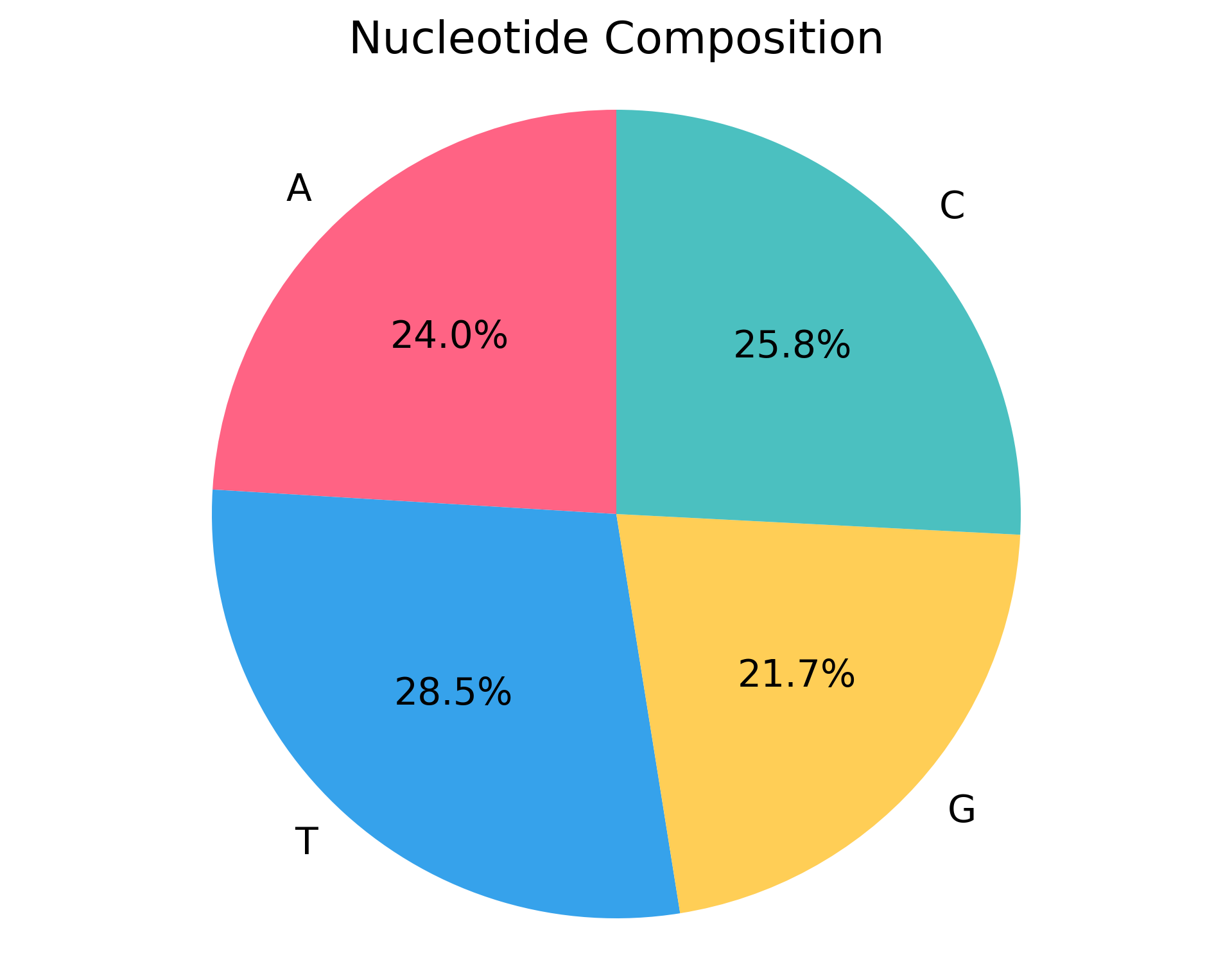
输入序列
>seq1|Human_BRCA1_fragment
ATGGATTTATCTGCTCTTCGCGTTGAAGAAGTACAAAATGTCATTAATGCTATGCAGAAAATCTTAGAGTGTCCCATCTGTCTGGAGTTGATCAAGGAACCTGTCTCCACAAAGTGTGACCACATATTTTGCAA
>seq2|Mouse_p53_fragment
ATGACTGCCATGGAGGAGTCACAGTCGGATATCAGCCTCGAGCTCCCTCTGAGCCAGGAGACATTTTCAGGCTTATGGAAACTGTGAGTGGATCCATTGGAAGGGCAGGCCCACCACCCCGAGGCTGCTCCCCCA
>seq3|E.coli_lacZ_fragment
ATGACCATGATTACGGATTCACTGGCCGTCGTTTTACAACGTCGTGACTGGGAAAACCCTGGCGTTACCCAACTTAATCGCCTTGCAGCACATCCCCCTTTCGCCAGCTGGCGTAATAGCGAAGAGGCCCGCACC
>seq4|Coronavirus_spike_fragment
ATGTTTGTTTTTCTTGTTTTATTGCCACTAGTCTCTAGTCAGTGTGTTAATCTTACAACCAGAACTCAATTACCCCCTGCATACACTAATTCTTTCACACGTGGTGTTTATTACCCTGACAAAGTTTTCAGATCC
>seq5|Arabidopsis_RuBisCO_fragment
ATGGCTTCCTCTATGCTCTCCTCCGTATCAGCAGTCGCCGTTACGAATCTGGTGTTATCCGTTAAGAATTCCAACCCTACTAAGGTTTGGCCTCAAGCTCAGGCTGAGGCGAAGGTTGGTATTTCGGATTTGAAT
独热编码可视化
下图显示了第一个序列(seq1)前30个核苷酸的独热编码示例。红色表示值为1,白色表示值为0。
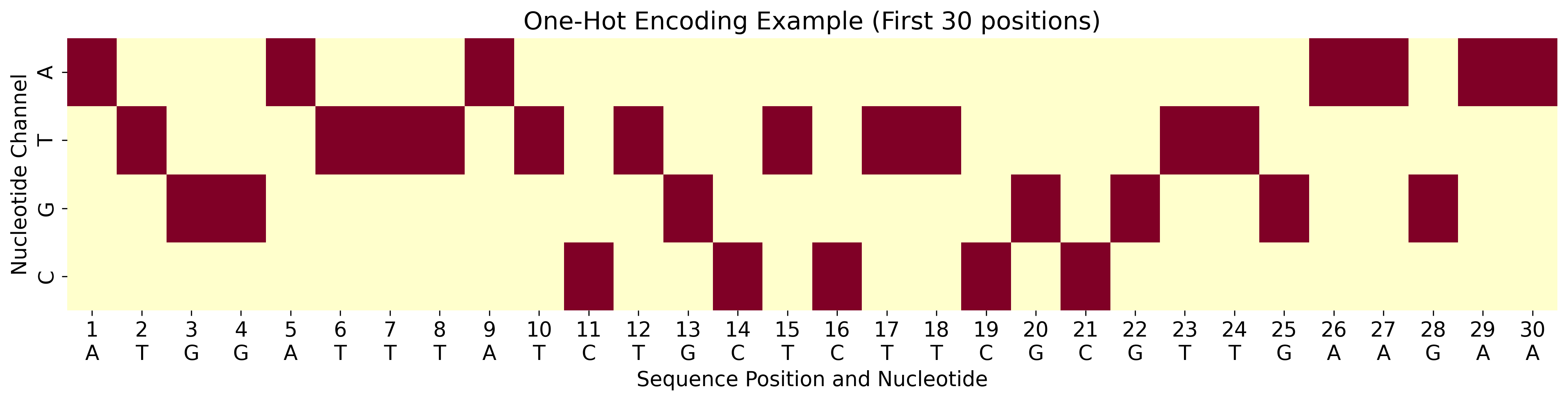
第一个序列的独热编码矩阵 (前20个位置)
| 位置 | 核苷酸 | A通道 | T通道 | G通道 | C通道 |
|---|---|---|---|---|---|
| 1 | A | 1 | 0 | 0 | 0 |
| 2 | T | 0 | 1 | 0 | 0 |
| 3 | G | 0 | 0 | 1 | 0 |
| 4 | G | 0 | 0 | 1 | 0 |
| 5 | A | 1 | 0 | 0 | 0 |
| 6 | T | 0 | 1 | 0 | 0 |
| 7 | T | 0 | 1 | 0 | 0 |
| 8 | T | 0 | 1 | 0 | 0 |
| 9 | A | 1 | 0 | 0 | 0 |
| 10 | T | 0 | 1 | 0 | 0 |
| 11 | C | 0 | 0 | 0 | 1 |
| 12 | T | 0 | 1 | 0 | 0 |
| 13 | G | 0 | 0 | 1 | 0 |
| 14 | C | 0 | 0 | 0 | 1 |
| 15 | T | 0 | 1 | 0 | 0 |
| 16 | C | 0 | 0 | 0 | 1 |
| 17 | T | 0 | 1 | 0 | 0 |
| 18 | T | 0 | 1 | 0 | 0 |
| 19 | C | 0 | 0 | 0 | 1 |
| 20 | G | 0 | 0 | 1 | 0 |
注: 表格仅显示前20个位置的独热编码。实际结果包含完整序列的所有位置。