文本相似度与预训练语言模型
工具说明
文本相似度与预训练语言模型工具结合了文本相似度计算和先进的预训练语言模型,用于分析医疗文本的语义相似性和关系。 该工具利用预训练语言模型(如BERT、BioBERT)将医疗文本转换为语义向量,然后使用余弦相似度等方法计算文本之间的相似程度。
主要功能包括:
- 文本语义向量化:将医疗文本转换为高维语义向量表示
- 文本相似度计算:计算文档之间的语义相似度
- 相似文档检索:基于语义相似度查找相关文档
- 文本聚类:根据语义相似性对文档进行聚类
- 文本语义可视化:将文本语义映射到低维空间进行可视化
该工具支持TXT、CSV和JSON格式的文本文件,适用于处理临床记录、医学文献和病例报告等医疗文本数据。
数据上传与参数设置
分析结果
上传文本数据并运行分析后,结果将显示在这里
分析完成!
您的文本数据已成功进行相似度分析。
处理结果摘要
| 处理文档数 | 5 |
|---|---|
| 平均文档长度 | 215 字符 |
| 使用语言模型 | BioBERT |
| 相似度指标 | 余弦相似度 |
| 向量维度 | 768 |
| 相似文档对数量 | 2 |
| 处理时间 | 3.45 秒 |
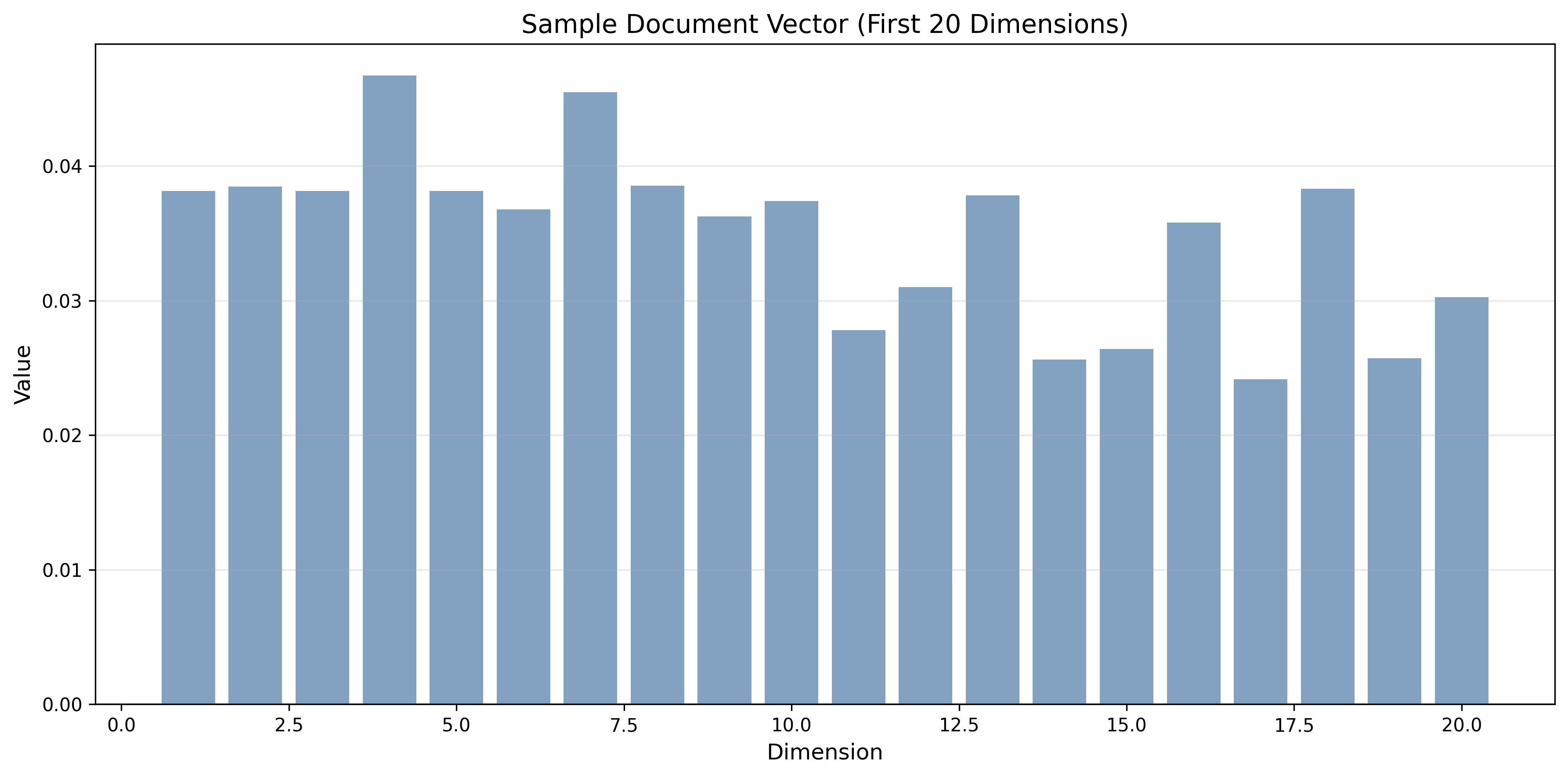
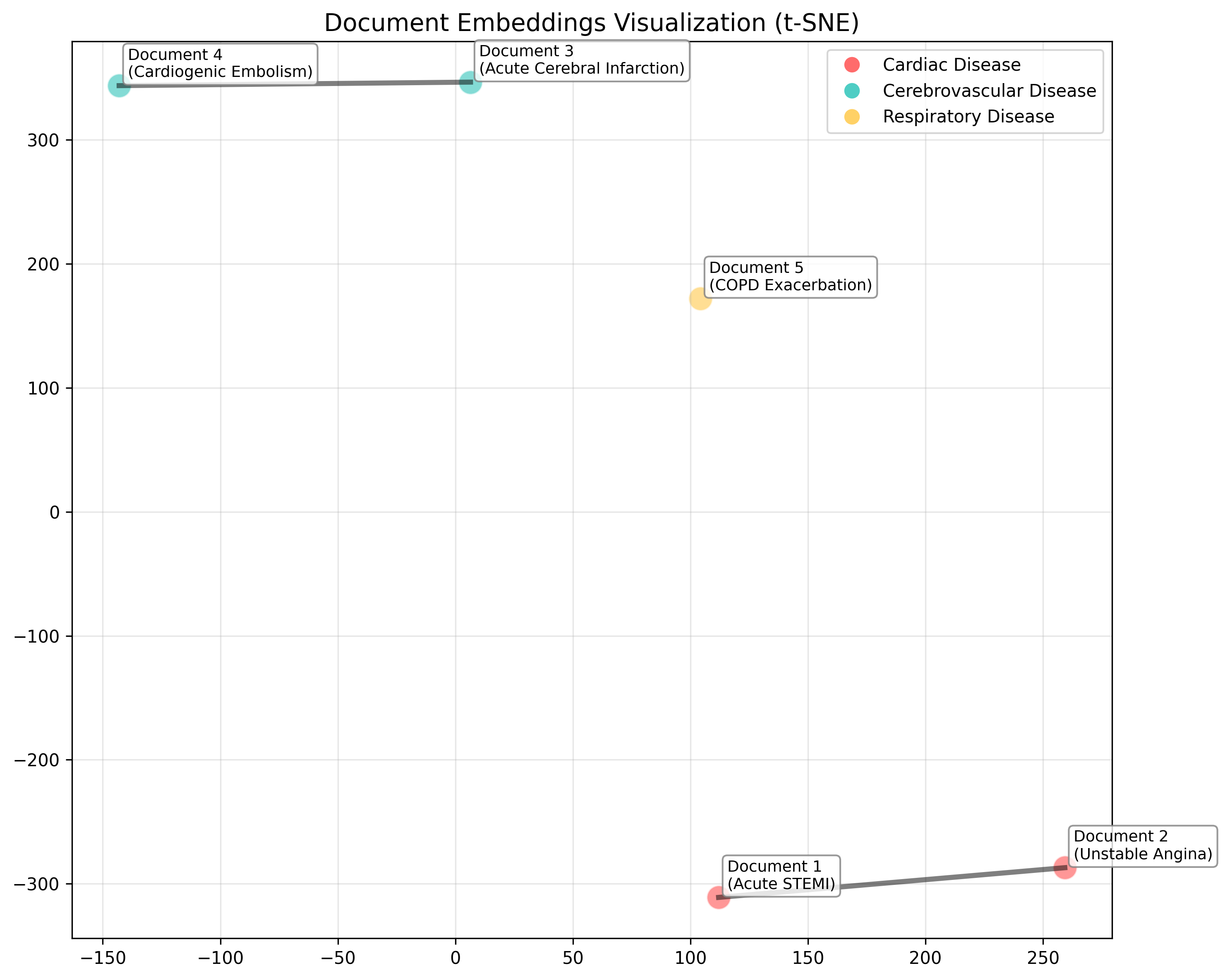
文本嵌入可视化
文档相似度矩阵
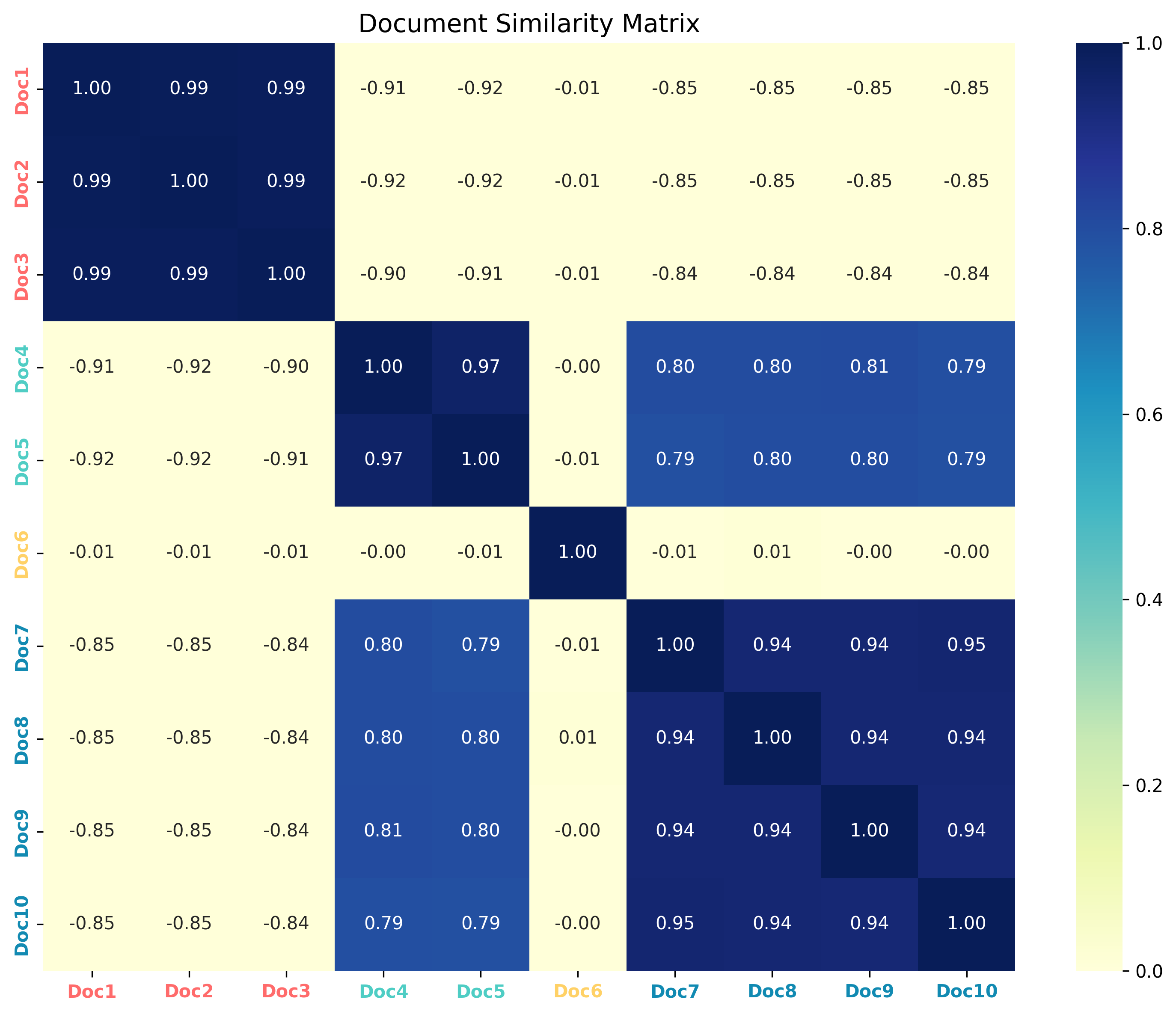
| 文档1 | 文档2 | 文档3 | 文档4 | 文档5 | |
|---|---|---|---|---|---|
| 文档1 | 1.00 | 0.85 | 0.42 | 0.45 | 0.32 |
| 文档2 | 0.85 | 1.00 | 0.38 | 0.41 | 0.28 |
| 文档3 | 0.42 | 0.38 | 1.00 | 0.76 | 0.25 |
| 文档4 | 0.45 | 0.41 | 0.76 | 1.00 | 0.23 |
| 文档5 | 0.32 | 0.28 | 0.25 | 0.23 | 1.00 |
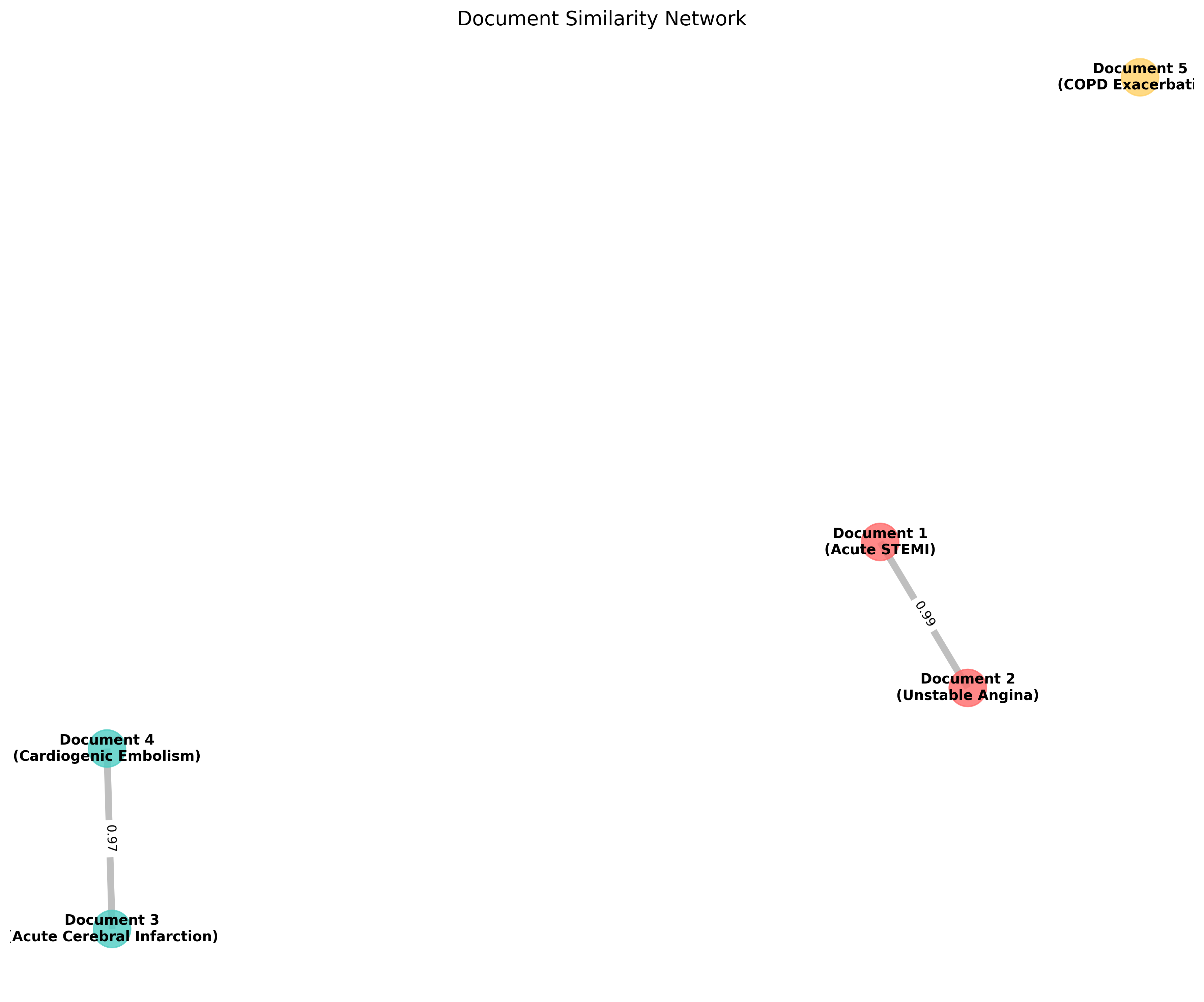
- 文档1和文档2 (相似度: 0.85) - 心脏类疾病组
- 文档3和文档4 (相似度: 0.76) - 脑血管类疾病组
相似文档对比
文档1 (急性ST段抬高型心肌梗死): 患者男性,63岁,因"反复胸闷、胸痛3个月,加重伴气促2天"入院。既往有冠心病、高血压、2型糖尿病病史多年。查体:血压156/92mmHg,心率96次/分,双肺底可闻及少许湿啰音。心电图示V1-V4导联ST段抬高0.2-0.4mV。心肌酶谱:肌钙蛋白T 2.5ng/mL,CK-MB 42U/L。超声心动图:左室前壁运动减弱,EF 45%。冠状动脉造影:前降支近段90%狭窄,右冠近段80%狭窄。诊断:急性ST段抬高型心肌梗死。
文档2 (不稳定型心绞痛): 患者女性,68岁,以"发作性胸痛、胸闷伴出汗1周"就诊。既往高脂血症10年。体检:BP 150/90mmHg,HR 88次/分,心尖区可闻及Ⅲ/Ⅵ级收缩期杂音。心电图示导联Ⅱ、Ⅲ、aVF ST段水平压低0.1mV。心肌标志物轻度升高:肌钙蛋白I 0.78ng/mL。超声示:室间隔增厚,左室射血分数52%。冠脉CT:左前降支中段70%狭窄,回旋支50%狭窄。诊断:不稳定型心绞痛。
关键共同概念:
- 症状: 胸闷、胸痛
- 检查结果: 心电图异常、肌钙蛋白升高、超声异常
- 影像学: 冠状动脉狭窄
- 诊断类型: 冠心病相关疾病
文档3 (急性脑梗死): 患者男,72岁,因"间断头晕、视物旋转伴恶心3天"入院。患者既往有高血压、脑梗死病史。查体:血压162/95mmHg,双侧巴彬斯基征阳性。头颅MRI示:左侧丘脑及放射冠区域新发缺血灶,左侧基底节区陈旧性脑梗死。颈部血管超声:双侧颈动脉斑块形成,左侧颈内动脉狭窄约50%。实验室检查:总胆固醇6.2mmol/L,低密度脂蛋白4.3mmol/L。诊断:急性脑梗死,动脉粥样硬化。
文档4 (心源性脑栓塞): 患者女性,58岁,因"突发右侧肢体无力、言语不清30分钟"急诊入院。既往有房颤、高血压病史。入院查体:清醒,构音障碍,右侧肢体肌力IV级,右侧Babinski征阳性。急诊头颅CT未见明显异常。24小时后复查头颅MRI:左侧大脑中动脉供血区急性脑梗死。实验室检查示D-二聚体0.9mg/L,INR 1.1。心电图:心房颤动。诊断:1.心源性脑栓塞 2.阵发性房颤。
关键共同概念:
- 神经系统症状: 神经功能障碍
- 体征: 巴彬斯基征阳性
- 影像学: 头颅MRI显示脑梗死
- 诊断类型: 脑血管疾病
文档相似度网络
文档向量示例